How Vector Databases Power AI Memory
Vector databases are the secret sauce behind AI systems that remember. Discover how they transform raw data into semantic memory, enabling chatbots, RAG applications, and AI assistants to maintain context across millions of interactions.

Table of Contents
- What Exactly Is a Vector Database?
- The Magic of Vector Embeddings
- How Similarity Search Actually Works
- Enter ANN: Approximate Nearest Neighbor
- The Big Four: Vector Database Comparison
- Qdrant: The Performance Leader
- Pinecone: The Easy Button
- Weaviate: The Hybrid Specialist
- Milvus: The Scale Champion
- From Memory to Intelligence: The RAG Architecture
- Real-World Applications in 2025
- Enterprise Knowledge Search
- AI Assistants with Persistent Memory
- Code Intelligence
- Recommendation Systems
- Multimodal Search
- Performance at Scale
- The Future: Agentic RAG and Beyond
- Agentic RAG
- Self-Updating Memory
- Edge Deployment
- Governance and Provenance
- Building Your First Vector-Powered Application
- Conclusion: Memory Is the Differentiator
Have you ever wondered how ChatGPT can recall details from earlier in a conversation, or how your AI assistant seems to “remember” your preferences over time? The answer lies in a piece of technology that’s become foundational to modern AI: vector databases.
They’re not your typical databases. Instead of storing rows and columns, they store mathematical representations of meaning—and they’re revolutionizing how AI systems maintain memory at scale.
What Exactly Is a Vector Database?
A vector database is a specialized database designed to store, index, and query high-dimensional vectors—numerical representations (embeddings) that capture the semantic meaning of data. Unlike traditional databases that match exact keywords, vector databases find data based on semantic similarity.
Here’s what that means in practice:
Imagine you have a document about “machine learning algorithms.” In a traditional database, searching for “ML models” might return nothing—no keyword match. But in a vector database, the system understands that “ML models” and “machine learning algorithms” are semantically related. It retrieves relevant results because their vector representations are close together in multi-dimensional space.
The Magic of Vector Embeddings
Before data can enter a vector database, it needs to become a vector. This process is called embedding, and it’s where the magic begins.
# Example: Creating embeddings with a transformer model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
text = "Vector databases power AI memory systems"
embedding = model.encode(text)
# embedding is now a 384-dimensional vector: [0.023, -0.142, 0.567, ...]
print(f"Dimensions: {len(embedding)}") # 384Embedding models—typically transformer-based neural networks—analyze the relationships between words, sentences, or even images and produce dense vectors where:
- Similar concepts cluster together in vector space
- Distance between vectors correlates with semantic difference
- The dimension count (typically 768-1536 for text) captures nuance
 How raw text becomes a searchable vector
How raw text becomes a searchable vector
How Similarity Search Actually Works
Once you have vectors stored, searching becomes a geometry problem. The most common approach is cosine similarity, which measures the cosine of the angle between two vectors.
cos(θ) = (A · B) / (||A|| × ||B||)
The result ranges from -1 to 1:
- 1 = Perfect match (vectors point in same direction)
- 0 = No relationship (orthogonal vectors)
- -1 = Opposite meaning
But here’s the challenge: computing cosine similarity between a query and millions of stored vectors? That’s O(N) time—far too slow for real-time applications.
Enter ANN: Approximate Nearest Neighbor
Vector databases don’t compute exact similarities. Instead, they use Approximate Nearest Neighbor (ANN) algorithms that sacrifice a tiny bit of accuracy for massive speed gains.
The most popular approaches:
| Algorithm | How It Works | Best For |
|---|---|---|
| HNSW | Multi-layer graph traversal | High recall, low latency |
| LSH | Hash similar items to same buckets | Memory efficiency |
| IVF | Partition into clusters, search relevant ones | Large-scale deployments |
| PQ | Compress vectors into codes | Storage constraints |
HNSW (Hierarchical Navigable Small World) dominates most implementations due to its excellent recall-to-latency ratio—achieving O(log N) query complexity while maintaining 95%+ accuracy.
 From query to results in milliseconds
From query to results in milliseconds
The Big Four: Vector Database Comparison
The vector database landscape has matured significantly. Here’s how the leading options stack up in 2025:
Qdrant: The Performance Leader
Written in Rust, Qdrant delivers exceptional performance with the lowest memory footprint in its class. Key stats:
- Latency: P95 <10ms for 10M vectors
- Throughput: 8,000-15,000 QPS
- Strength: Advanced metadata filtering, self-hosting flexibility
- Best for: Edge deployments, cost-conscious scaling
Pinecone: The Easy Button
Fully managed, cloud-only, and designed for teams who want zero infrastructure headaches:
- Setup: Literally 5 lines of code
- Compliance: SOC 2, HIPAA, GDPR out of the box
- Best for: Enterprise SaaS applications
Weaviate: The Hybrid Specialist
Open-source with built-in vectorization modules (OpenAI, Cohere, HuggingFace integrations):
- Unique feature: Knowledge graph + vector search
- API: GraphQL for complex queries
- Best for: Applications requiring semantic + structured search
Milvus: The Scale Champion
Built for billions to trillions of vectors with distributed architecture:
- Scale: Enterprise-grade horizontal scaling
- Performance: GPU-accelerated searches at 5ms latency
- Best for: Massive datasets with data engineering teams
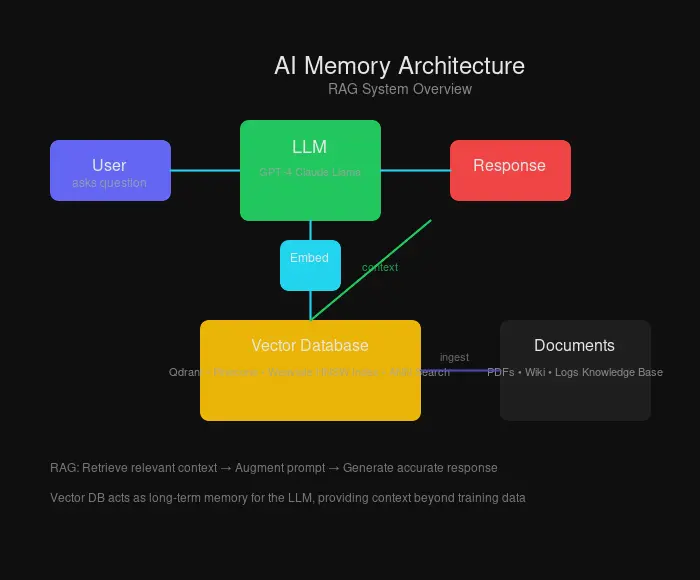 How vector databases fit into an AI memory stack
How vector databases fit into an AI memory stack
From Memory to Intelligence: The RAG Architecture
Here’s where it all comes together. Retrieval-Augmented Generation (RAG) is the architecture that turns vector databases into AI memory:
- Ingest: Documents are chunked and embedded
- Store: Vectors land in the database with metadata
- Query: User question becomes a query embedding
- Retrieve: ANN search finds relevant context
- Augment: Context is injected into the LLM prompt
- Generate: LLM produces accurate, grounded responses
This pattern solves the fundamental limitation of LLMs: their training data is frozen in time. With RAG, AI systems can access:
- Real-time information
- Proprietary company documents
- Conversation history
- Any data you choose to embed
Real-World Applications in 2025
The vector database market has exploded to $2.58 billion in 2025, with projected growth to $3.2 billion by 2026. Here’s what’s driving adoption:
Enterprise Knowledge Search
Companies embed internal documentation, wikis, and Slack history. Employees ask natural language questions and get semantically relevant answers—not just keyword matches.
AI Assistants with Persistent Memory
Personal AI assistants use vector databases to recall conversations, preferences, and context across sessions. Your AI remembers that you mentioned being vegetarian last month when recommending restaurants today.
Code Intelligence
Developers search codebases semantically. “Find authentication middleware” returns relevant code even if the exact phrase never appears.
Recommendation Systems
E-commerce platforms embed products and users. Similar vectors indicate likely purchase patterns. No more “you bought a lamp, here are ten more lamps.”
Multimodal Search
Modern systems search across text, images, and audio simultaneously. Upload a photo of clothing and find visually similar items—but also text descriptions that match the style.
Performance at Scale
What does “scale” actually mean? Here are typical production benchmarks:
| Metric | Small Deployment | Enterprise |
|---|---|---|
| Vectors | 1-10 million | Billion+ |
| Dimensions | 768-1536 | 1536-4096 |
| Query Latency | 10-30ms P95 | <50ms P95 |
| Throughput | 1,000-5,000 QPS | 10,000+ QPS |
| Storage Cost | $100-300/month | $500-2000/month |
The cost differential between self-hosting and managed services narrows as you scale—at enterprise levels, operational overhead often exceeds infrastructure savings.
The Future: Agentic RAG and Beyond
Vector database technology is rapidly evolving. Key trends for 2025-2026:
Agentic RAG
AI agents that dynamically adjust retrieval strategies, cross-check sources, and reason over relationships before answering. Not just retrieving chunks—understanding connections.
Self-Updating Memory
Systems like MemoryLLM can integrate new knowledge without full retraining. Vector databases become truly living memory.
Edge Deployment
Optimized vector stores running on local devices. Your phone’s AI assistant with billions of parameters—and local memory to match.
Governance and Provenance
Enterprise requirements for data lineage. Which source informed which answer? How confident is the retrieval?
Building Your First Vector-Powered Application
Getting started is easier than ever. Here’s a minimal example using Qdrant:
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
# Initialize
client = QdrantClient(":memory:") # Or connect to a server
model = SentenceTransformer('all-MiniLM-L6-v2')
# Embed and store
texts = ["AI memory systems use vector databases",
"Embeddings capture semantic meaning"]
embeddings = model.encode(texts)
client.upsert(
collection_name="my_docs",
points=[... # Create points from embeddings
)
# Query
query_embedding = model.encode("How do AI systems remember?")
results = client.search(
collection_name="my_docs",
query_vector=query_embedding,
limit=5
)The pattern is remarkably consistent across providers: embed → store → query. The differences emerge in performance characteristics, deployment options, and specialized features.
Conclusion: Memory Is the Differentiator
We’ve moved past the era where AI systems were judged solely on model size or training data. The new frontier is memory—the ability to maintain context, learn from interactions, and access knowledge beyond training cutoffs.
Vector databases are the infrastructure that makes this possible. They transform the stochastic, forgetful nature of LLMs into something more like a persistent intelligence.
Whether you’re building a chatbot that remembers conversations, a search system that understands intent, or an AI assistant that truly knows your preferences—vector databases are no longer optional. They’re foundational.
The technology is mature. The tooling is excellent. The market is growing. If you’re working with AI and haven’t explored vector databases yet, there’s no better time than now.
Ready to dive deeper? Check out Qdrant, Pinecone, Weaviate, and Milvus documentation. Each offers free tiers perfect for experimentation.

Comments
Powered by GitHub Discussions