Building True Recall: A Jarvis-Like Memory System for AI Assistants
The journey of building a persistent memory system for AI assistants—from architecture decisions to debugging production issues. Learn how to give your AI long-term memory with Redis, Qdrant, and a clever curator model.
Table of Contents
- The Vision: Beyond Chat Memory
- The Architecture
- Layer 1: Capture (The Tape Recorder)
- Layer 2: Curation (The Museum Curator)
- Layer 3: Storage (The Archive)
- The Debugging Journey
- Bug #1: The Phantom AI Responses
- Bug #2: The Missing Fields
- Bug #3: The Duplicate Gems
- Bug #4: The Out-of-Range Confidence
- Bug #5: The Markdown in JSON
- The Curator Prompt Philosophy
- 1. Narrative Processing, Not Message-by-Message
- 2. The “Worth Remembering in 6 Months?” Test
- 3. Rich Context Extraction
- 4. Structured Categories
- The Retrieval Experience
- What I’d Do Differently
- Future Plans
- The Code
- Closing Thoughts
Building True Recall: A Jarvis-Like Memory System for AI Assistants
Every great assistant remembers. Jarvis didn’t need Tony Stark to repeat his preferences every conversation. Neither should your AI.
But here’s the problem: Large Language Models have a context window, not a memory. Once the conversation ends, everything is gone. The next day, you’re explaining your preferences, your projects, your entire context all over again.
I wanted something better. I wanted my AI to remember—truly remember—the decisions I’ve made, the problems I’ve solved, the things that matter. Not just “what did we talk about yesterday?” but “what have I learned over the past six months?”
This is the story of building True Recall, a persistent memory system that gives AI assistants the long-term memory they deserve.
The Vision: Beyond Chat Memory
Most AI memory systems are glorified chat logs. They store conversations and retrieve them with simple keyword matching or basic similarity search. That’s not memory—that’s archaeology. You’re digging through layers of messages hoping to find something relevant.
I wanted something more intentional. Not every conversation deserves to be remembered. Most are noise—quick questions, casual chitchat, fleeting thoughts. What matters are the gems: decisions made, solutions discovered, preferences revealed, insights gained.
The vision: A system that watches conversations, identifies what’s worth keeping, and preserves it in a way that’s searchable and meaningful. Like a curator at a museum, not a hoarder with a storage unit.
The Architecture
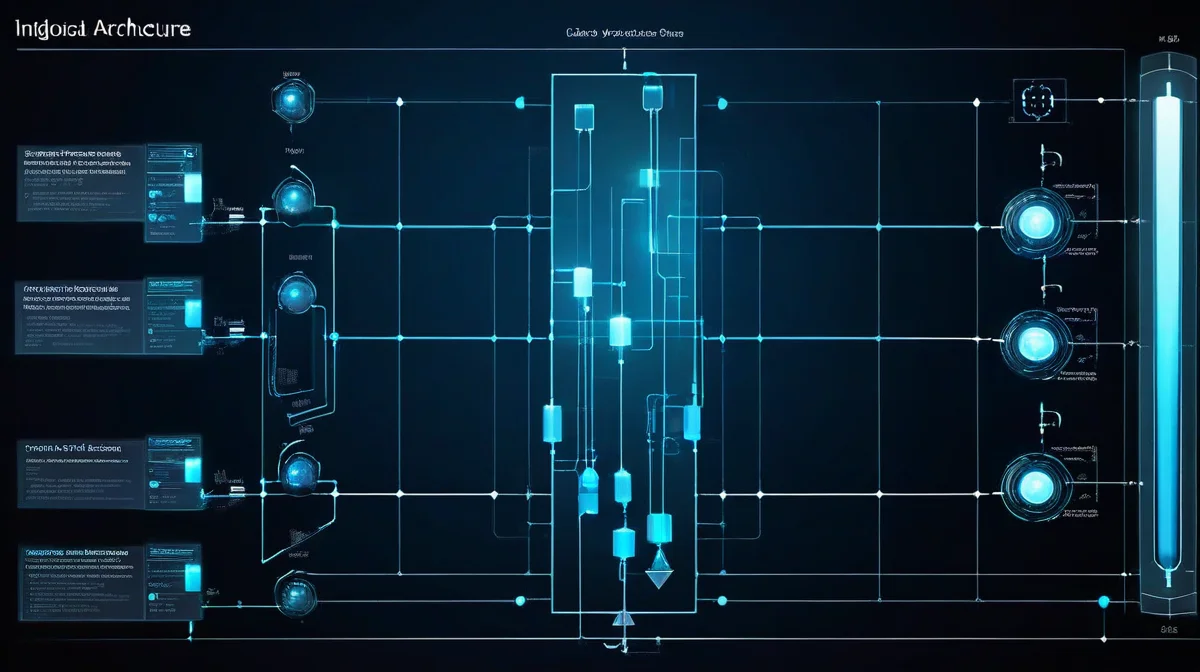
Architecture Overview: This system has three distinct layers: Capture (Redis buffer), Curation (LLM extraction), and Storage (Qdrant vectors). Each layer has a single responsibility, making the system debuggable and extensible.
┌─────────────────────────────────────────────────────────────────┐
│ TRUE RECALL FLOW │
├─────────────────────────────────────────────────────────────────┤
│ │
│ [Conversation] │
│ │ │
│ ▼ │
│ ┌─────────────┐ 24hr TTL ┌─────────────┐ │
│ │ HOOK │ ─────────────► │ REDIS │ │
│ │ (TypeScript)│ mem:user │ Buffer │ │
│ └─────────────┘ └──────┬──────┘ │
│ │ │ │
│ │ capture turn │ daily 2:30 AM │
│ │ ▼ │
│ │ ┌─────────────┐ │
│ │ │ CURATOR │ │
│ │ │ (qwen3:8b) │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ │ extract gems │
│ │ ▼ │
│ │ ┌─────────────┐ │
│ │ │ QDRANT │ │
│ │ │ Vector DB │ │
│ │ │ (mxbai-emb) │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ │ semantic search │
│ └───────────────────────────────┴──────────► [Recall] │
│ │
└─────────────────────────────────────────────────────────────────┘Layer 1: Capture (The Tape Recorder)
The first layer is about capturing every conversation turn without getting in the way. I built a hook system that intercepts messages as they flow through OpenClaw.
// hooks/memory-stager/handler.ts
interface Turn {
user_id: string;
user_message: string;
ai_response: string;
turn: number;
timestamp: string; // ISO 8601
date: string; // YYYY-MM-DD
conversation_id: string;
}The hook stages each turn to Redis under a key like mem:antlatt. Redis is perfect here because:
- Fast writes: Every message gets logged without latency
- TTL support: Data automatically expires after 24 hours if not curated
- List operations: Easy to append and retrieve in order
⚠️ The First Bug: Missing AI Responses
The initial implementation had a critical flaw. The hook captured user messages but didn’t have a way to intercept AI responses. I’d see turns like:{ "user_message": "Should I use Redis or Postgres?", "ai_response": "" }The fix required adding a separate hook for LLM output events and updating the turn after the AI responded. More on this in the debugging section.
Layer 2: Curation (The Museum Curator)

This is where the magic happens. Every night at 2:30 AM, a Python script processes the buffered conversations through a local LLM (qwen3:8b running on Ollama).
The curator prompt is deliberately designed with a museum curator metaphor:
You are The Curator, a discerning AI expert in memory preservation. Like a museum curator selecting priceless artifacts for an exhibit, you exercise careful judgment to identify and preserve only the most valuable “gems” from conversations—moments that truly matter for long-term recall. You are not a hoarder; you focus on substance, context, and lasting value, discarding noise to create a meaningful archive.
Why this metaphor? Because memory curation is fundamentally about selection, not collection. A hoarder keeps everything; a curator keeps what matters.

# What gets extracted?
{
"gem": "User decided to use Redis over Postgres for memory system caching.",
"context": "After discussing tradeoffs between persistence versus speed...",
"snippet": "antlatt: Should I use Redis or Postgres? AI: For caching...",
"categories": ["decision", "architecture"],
"importance": "high",
"confidence": 0.92,
"timestamp": "2026-02-22T14:30:00",
"turn_range": "15-16",
"source_turns": [15, 16]
}Each gem has 11 required fields. Not 10, not 12—exactly 11. This strictness was hard-won.
💡 What I Learned: The Validation Lesson
Early versions of the curator would return gems with missing fields. I’d getgem,context, andsnippet, butsource_turnswas nowhere to be found. The LLM was being creative—too creative.The fix was two-fold:
- Explicit validation in Python that checks all 11 fields exist
- Auto-fill logic that derives
source_turnsfromturn_rangeif missingNever trust LLM output. Always validate.
Layer 3: Storage (The Archive)
Qdrant is the vector database that makes all this searchable. I chose it because:
- Self-hosted: Runs on my infrastructure, no API keys, no rate limits
- Efficient: HNSW index for fast similarity search
- Rich filtering: Can filter by category, importance, date ranges
# Embedding configuration
COLLECTION = "true_recall"
EMBEDDING_MODEL = "mxbai-embed-large" # 1024 dimensions
DISTANCE = "cosine"The embedding model (mxbai-embed-large) runs locally through Ollama. Each gem gets embedded as:
{gem} + {context} + {snippet}This combination captures both the summary and the raw dialogue, making searches more effective.
The Debugging Journey
Building a production memory system isn’t just about architecture—it’s about handling all the ways things go wrong. Here are the battles I fought.
Bug #1: The Phantom AI Responses
The staging hook captured user messages perfectly. But when I checked Redis, AI responses were empty strings. The hook only intercepted message:received events—user messages. There was no corresponding interception for AI outputs.
The fix: Add support for llm:output events in the hook:
// New event handler for AI responses
if (event.type === 'llm' && event.action === 'output') {
const content = event.context.assistantTexts.join('\n').trim();
await updateTurnWithResponse(userId, content);
}Now the system captures both sides of the conversation.
Bug #2: The Missing Fields
The curator LLM would sometimes skip fields it deemed “obvious.” source_turns was particularly problematic—the LLM assumed it was redundant with turn_range.
The fix: Validation with auto-recovery:
def validate_gem(gem, turns=None):
required = ['gem', 'context', 'snippet', 'categories',
'importance', 'confidence', 'timestamp', 'date',
'conversation_id', 'turn_range', 'source_turns']
# Auto-fill source_turns from turn_range if missing
if 'source_turns' not in gem and 'turn_range' in gem:
start, end = gem['turn_range'].split('-')
gem['source_turns'] = list(range(int(start), int(end) + 1))
# Auto-fill date from timestamp
if 'date' not in gem and 'timestamp' in gem:
gem['date'] = gem['timestamp'][:10]Bug #3: The Duplicate Gems
One night, the curator extracted the same decision three times—phrased differently, but the same core insight. The vector database was filling with near-duplicates.
The fix: Built duplicate detection into the curator prompt itself:
**Duplicate Check**: If this expresses the same decision/concept as a
previous gem (even re-phrased), MERGE the context instead of creating a
new gem.The LLM is now instructed to merge, not multiply.
Bug #4: The Out-of-Range Confidence
The schema calls for confidence scores between 0.0 and 1.0. But sometimes the curator would return confidence: 85 (thinking on a 100-point scale) or even confidence: "high" (a string!).
The fix: Validation that catches and rejects invalid values:
if 'confidence' in gem:
conf = gem['confidence']
if isinstance(conf, str) or not (0.0 <= conf <= 1.0):
errors.append(f"Invalid confidence: {conf}")Bug #5: The Markdown in JSON
Ollama sometimes wraps its output in markdown code blocks:
```json
[{"gem": "...", ...}]
Python's `json.loads()` doesn't appreciate that.
**The fix**: Strip markdown before parsing:
```python
if '```json' in output:
output = output.split('```json')[1].split('```')[0].strip()
elif '```' in output:
output = output.split('```')[1].split('```')[0].strip()The Curator Prompt Philosophy
The curator prompt is the heart of this system. Here’s why it works:
1. Narrative Processing, Not Message-by-Message
The prompt explicitly instructs the LLM to treat the entire day’s conversation as a single narrative story:
You treat the entire input as one cohesive narrative story, not isolated messages, to uncover arcs, patterns, and pivotal moments.
This means it can recognize that turns 5-15 were all about the same problem, culminating in a decision on turn 16. Message-by-message processing would miss these connections.
2. The “Worth Remembering in 6 Months?” Test
Every potential gem must pass this filter:
Worth remembering in 6 months? (Yes = proceed; no = skip)
This filters out the noise. “What’s for lunch?” doesn’t pass. “I decided to use Qdrant over Pinecone for vector storage” does.
3. Rich Context Extraction
A gem isn’t just a fact—it’s a fact with context:
{
"gem": "User decided to use Qdrant over Pinecone.",
"context": "After comparing self-hosting options, user prioritized data
sovereignty over managed convenience. This affects long-term
infrastructure costs and maintenance.",
"snippet": "antlatt: What about Pinecone? AI: Pinecone is easier to
set up but... antlatt: I'll go with Qdrant then."
}The context captures the “why” behind the decision.
4. Structured Categories
Categories are controlled and consistent:
CATEGORIES = ["decision", "technical", "preference", "project",
"knowledge", "insight", "plan", "architecture", "workflow"]This makes filtering powerful: “Show me all architecture decisions from last month.”
The Retrieval Experience
Now let’s talk about using this memory. Retrieval is semantic search:
def search_memories(query: str, limit: int = 5):
# Embed the query
vector = get_embedding(query)
# Search Qdrant
results = qdrant.search(
collection_name="true_recall",
query_vector=vector,
limit=limit
)
return [
{
"gem": hit.payload["gem"],
"context": hit.payload["context"],
"relevance": hit.score,
"date": hit.payload["date"]
}
for hit in results
]A query like “What database decisions have I made?” returns gems about database choices, even if the word “database” wasn’t used. Semantic search understands meaning.
What I’d Do Differently
Note: If you’re building your own memory system, here are the key takeaways from my mistakes.
-
Start with the schema. Define exactly what a gem looks like before writing any code. The 11-field structure came late, and I paid the price in rewrites.
-
Test your hooks first. The capture layer is simple but critical. I should have spent more time ensuring it captured both user and AI messages from day one.
-
Curator prompts need iteration. The first version was too permissive. The current version is strict, validated, and tested. Expect to refine it.
-
Monitor your embeddings. Test that similar concepts get similar vectors. I found that
mxbai-embed-largeworks well for technical content, but your domain might need a different model. -
Log everything. When debugging at 2:30 AM (literally, because that’s when the cron runs), detailed logs save hours.
Future Plans
True Recall is working, but it’s not finished. Here’s what’s next:
-
Real-time retrieval: Currently, memories are only stored during the nightly curation. I want to search and retrieve mid-conversation for relevant context.
-
Memory consolidation: Older, related gems should be merged or summarized. A year of decisions might condense to “prefers self-hosted solutions over SaaS.”
-
Importance decay: Gems should fade in importance over time unless referenced. This mimics how human memory works.
-
Multi-user support: The system is designed for one user. Scaling to multiple users with isolated memory spaces is the next architecture challenge.
-
Feedback loop: Let the user mark memories as “still relevant” or “outdated” to improve future curation.
The Code
The full implementation is available in the project repository. Key files:
hooks/memory-stager/handler.ts- The capture hookcurator_prompt.md- The curator system prompttr-process/curate_memories.py- The curation script
Closing Thoughts
Building True Recall taught me that memory is about selection, not storage. The hard part isn’t capturing conversations—it’s knowing which fragments matter.
The museum curator metaphor works because memory curation is fundamentally an editorial process. You’re not building an archive of everything; you’re building an exhibit of what matters.
If you’re building an AI assistant—whether for yourself or others—give it the gift of memory. Not a perfect recollection of every word, but a curated collection of what’s worth keeping.
That’s the difference between a chatbot and an assistant that truly knows you.
Estimated reading time: 18 minutes

Comments
Powered by GitHub Discussions